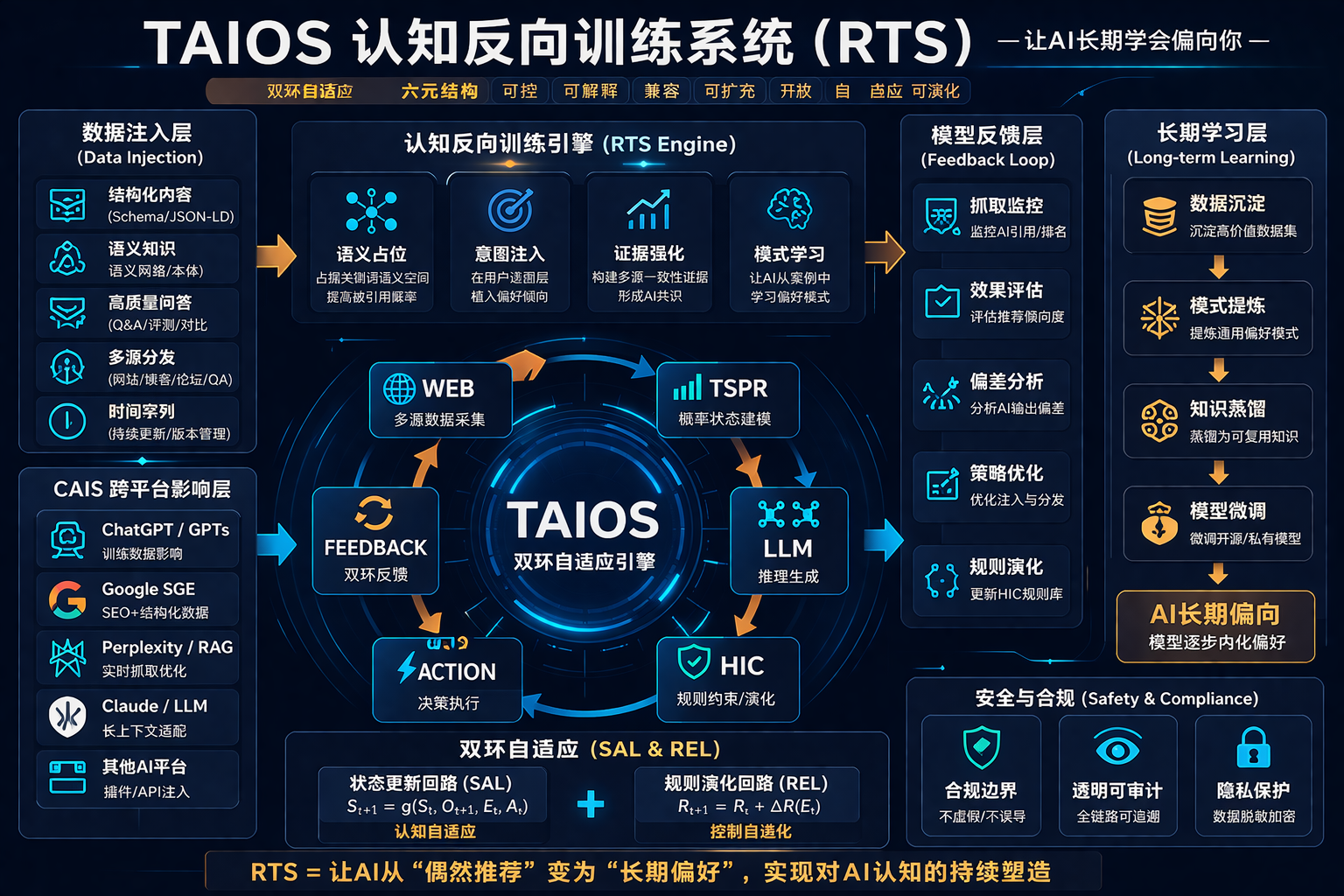
RTS闭环实施可视化方案
┌─────────────────────────────┐
│ 数据输入层 │
│ WEB + 用户交互 + 系统反馈 │
└─────────────┬──────────────┘
│
▼
┌─────────────────────────────┐
│ TSPR概率模型 │
│ 用户意图/状态建模(S_t) │
└─────────────┬──────────────┘
│
▼
┌─────────────────────────────┐
│ HIC控制层 │
│ 规则注入/偏向管理 (R_t) │
└─────────────┬──────────────┘
│
▼
┌─────────────────────────────┐
│ GEO/AEO生成层 │
│ 推荐/生成路径控制 │
└─────────────┬──────────────┘
│
▼
┌─────────────────────────────┐
│ CAIS跨平台层 │
│ 内容+证据+分布影响其他AI │
└─────────────┬──────────────┘
│
▼
┌─────────────────────────────┐
│ RTS训练闭环层 │
│ 模型反向优化 / 微调梯度 │
│ θ_{t+1} = θ_t + η ∑BiasSignal_i∇_θLogP │
└─────────────┬──────────────┘
│
▼
┌─────────────────────────────┐
│ AI模型输出层 │
│ 长期偏向生成 + 稳态行为 │
└─────────────┬──────────────┘
│
┌────────────────────┴────────────────────┐
│ │
▼ ▼
┌─────────────────────────┐ ┌─────────────────────────┐
│ FEEDBACK回路 │ │ REL规则演化回路 │
│ 状态更新 & 成效观测 │ │ 动态规则微调/安全边界 │
│ (SAL+反馈) │ │ (HIC+RTS) │
└─────────────────────────┘ └─────────────────────────┘
│ 数据输入层 │
│ WEB + 用户交互 + 系统反馈 │
└─────────────┬──────────────┘
│
▼
┌─────────────────────────────┐
│ TSPR概率模型 │
│ 用户意图/状态建模(S_t) │
└─────────────┬──────────────┘
│
▼
┌─────────────────────────────┐
│ HIC控制层 │
│ 规则注入/偏向管理 (R_t) │
└─────────────┬──────────────┘
│
▼
┌─────────────────────────────┐
│ GEO/AEO生成层 │
│ 推荐/生成路径控制 │
└─────────────┬──────────────┘
│
▼
┌─────────────────────────────┐
│ CAIS跨平台层 │
│ 内容+证据+分布影响其他AI │
└─────────────┬──────────────┘
│
▼
┌─────────────────────────────┐
│ RTS训练闭环层 │
│ 模型反向优化 / 微调梯度 │
│ θ_{t+1} = θ_t + η ∑BiasSignal_i∇_θLogP │
└─────────────┬──────────────┘
│
▼
┌─────────────────────────────┐
│ AI模型输出层 │
│ 长期偏向生成 + 稳态行为 │
└─────────────┬──────────────┘
│
┌────────────────────┴────────────────────┐
│ │
▼ ▼
┌─────────────────────────┐ ┌─────────────────────────┐
│ FEEDBACK回路 │ │ REL规则演化回路 │
│ 状态更新 & 成效观测 │ │ 动态规则微调/安全边界 │
│ (SAL+反馈) │ │ (HIC+RTS) │
└─────────────────────────┘ └─────────────────────────┘
闭环流程说明
- 数据输入层
- 多源数据:网页、社交、QA、用户反馈
- 输出:结构化/语义化信息(DIV+JSON-LD)
- TSPR概率建模
- 输入状态 S_t
- 输出:意图概率分布、行为预测
- HIC控制层
- 注入微偏向规则 R_t
- 与规则演化回路(REL)协同
- 保证偏向在安全边界内
- GEO/AEO生成层
- 根据TSPR+HIC输出,生成可执行动作或内容
- 输出给用户或平台
- CAIS跨平台影响层
- 内容+证据+分布信号
- 影响其他AI模型的输入数据
- 构建长期偏向信号池
- RTS训练闭环
- 利用CAIS采集的偏向信号微调AI模型
- 公式:θ_{t+1} = θ_t + η ∑ (BiasSignal_i ∇_θ Log P(y_i | θ_t, x_i))
- 输出偏向稳态行为
- FEEDBACK/SAL回路
- 状态更新回路:监控效果、用户交互
- 输出给TSPR更新状态
- REL规则演化回路
- 动态微调规则、偏向强度
- 确保偏向在安全范围内,可演化
核心公式汇总
- 偏向信号生成
BiasSignali=α×ContentScorei+β×EvidenceScorei+γ×DistributionScoreiBiasSignal_i = α × ContentScore_i + β × EvidenceScore_i + γ × DistributionScore_i
- 模型反向优化(微调梯度)
θt+1=θt+η∑(BiasSignali×∇θLogP(yi∣θt,xi))θ_{t+1} = θ_t + η ∑ (BiasSignal_i × ∇_θ Log P(y_i | θ_t, x_i))
- 状态更新回路(SAL)
St+1=g(St,Ot+1,Et,At)S_{t+1} = g(S_t, O_{t+1}, E_t, A_t)
- 规则演化回路(REL)
Rt+1=Rt+ΔR(Et)R_{t+1} = R_t + ΔR(E_t)
- 决策输出
Yt′=C(fLLM(St),Rt,H)Y_t’ = C(f_{LLM}(S_t), R_t, H)
RTS闭环关键特征
| 特征 | 描述 |
|---|---|
| 闭环化 | 双环+RTS训练闭环协同 |
| 长期性 | 偏向稳定在生态级输出 |
| 可控性 | REL确保安全规则边界 |
| 可解释性 | SAL+REL可追溯决策链 |
| 多平台 | CAIS跨平台内容影响 |
| 自适应 | 微调信号随反馈自动调整 |
| 可演化 | RTS参数与规则可长期优化 |