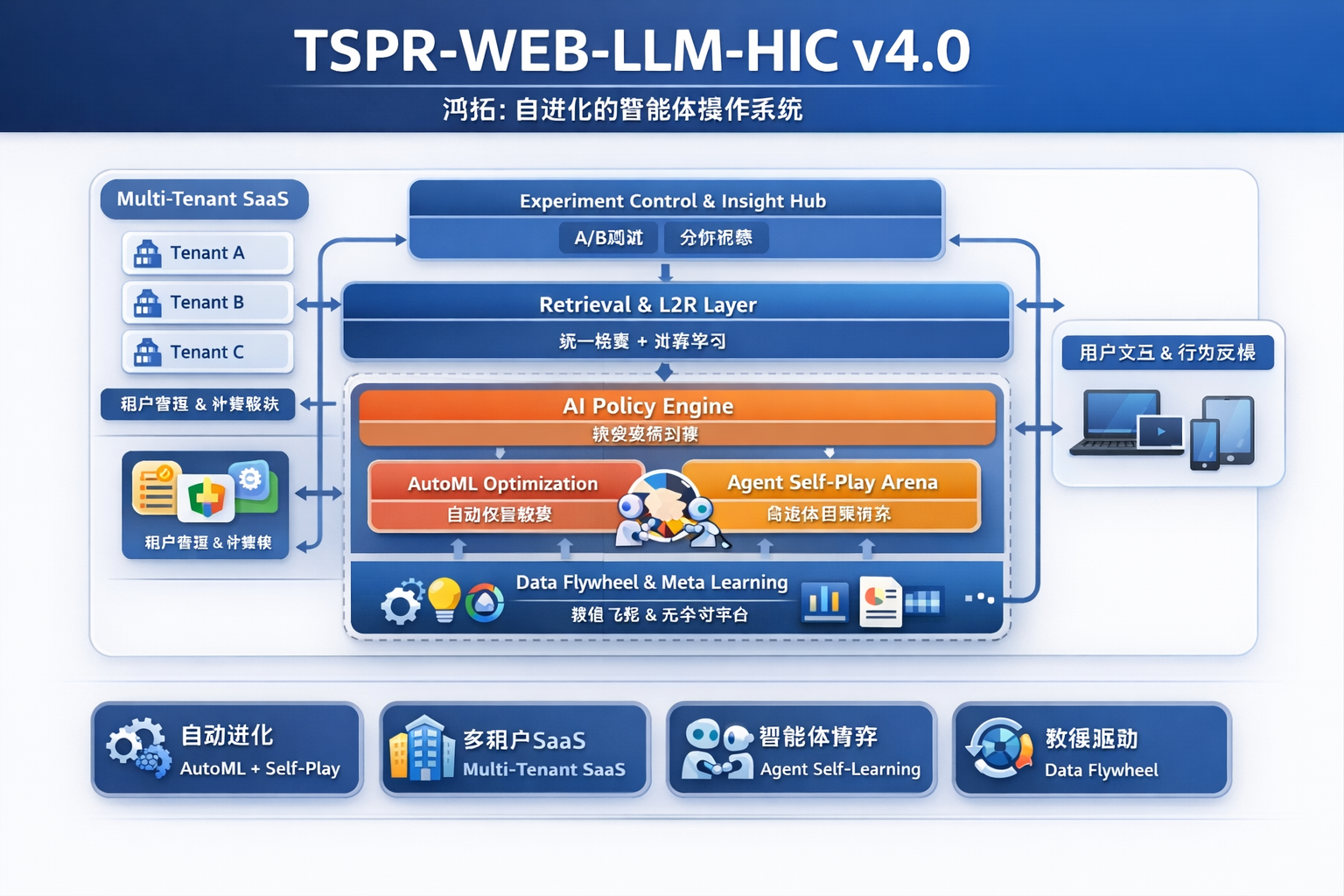
🚀 TSPR-WEB-LLM-HIC v4.0 核心升级
核心目标:
可扩展 + 自学习 + 多租户 + 自适应决策 + 数据飞轮
v3.0 已经解决了“数据碎片化 + Agent化 + 学习排序”,v4.0 就是把它变成 可运营、可成长、可投资的 AI 操作系统。
一、多租户 SaaS 架构
1.1 核心思想
- 每个企业/客户拥有 隔离的数据空间、策略和模型权重
- 核心服务统一多租户路由
- 权限和预算控制全链路
1.2 关键模块
| 模块 | 功能 |
|---|---|
| Tenant Manager | 管理租户信息、隔离数据、定制阈值 |
| Multi-Model Gateway | 每个租户可绑定不同模型策略 |
| Cost & Quota | 每租户成本控制 + Token 配额 |
| Config per Tenant | 权重、阈值、策略、Agent能力可定制 |
二、权重自动搜索(AutoML)
2.1 核心问题
- v3.0 Learning to Rank 的权重和特征仍需人工调优
- 不同租户、不同场景最优参数不同
2.2 AutoML 功能
- 离线训练:从历史日志采集信号 + CTR/CVR指标
- 自动搜索最优权重组合:XGBoost/神经排序器超参搜索
- A/B 测试自动验证:选择效果最佳策略自动上线
2.3 结果
系统自己找到“最适合场景和租户”的排序策略,不再依赖人工经验。
三、Agent 自博弈优化
3.1 核心思想
- LLM Agent 不只是被动执行
- 引入策略博弈机制,让 Agent 自动探索最优决策路径
- 支持自适应 prompt 调整、工具调用优化、反馈学习
3.2 实现方式
– reward = CTR/CVR + 成本节约 + 用户满意度
– 强化学习 + 离线模拟训练
3.3 结果
系统不断自我优化,LLM调用效率和准确率随时间提高
四、数据飞轮设计(闭环增长)
4.1 核心思想
- 系统行为 → 收集信号 → 离线训练 → 更新模型 → 决策更精准 → 再生成行为
- 形成自增强闭环
4.2 典型流程
4.3 成效
- 用户量越大,系统越聪明
- 各租户场景模型自适应提升
- 成本效率随使用增长不断优化
五、v4.0 与 v3.0 对比
| 维度 | v3.0 | v4.0 |
|---|---|---|
| 数据碎片化 | ✅统一检索 | ✅统一检索 + 租户隔离 |
| 排序策略 | Learning to Rank | ✅自动搜索权重 + 自适应 |
| LLM 调用 | Agent化 | ✅Agent自博弈优化 |
| 成本控制 | ROI驱动 | ✅租户级配额 + 优化决策 |
| 自学习 | 在线+离线 | ✅全闭环数据飞轮 |
| 可扩展性 | 单租户 | ✅多租户 SaaS |
六、v4.0 的本质价值
- AI操作系统:不仅是 LLM 决策系统,而是全链路自优化系统
- 闭环成长:使用越多,效果越好
- 企业级 SaaS:可多客户部署,数据隔离,定制策略
- 投资价值:真正的可扩展 AI 产品
TSPR-WEB-LLM-HIC v4.0 实施方案(落地版)
一、总体目标
- 多租户 SaaS 化:支持企业级客户隔离,策略定制,成本控制
- 自学习闭环:AutoML + Agent自博弈 + 数据飞轮
- 智能决策引擎:Learning to Rank + LLM Agent Router + Policy Engine
- 可观测 + 可扩展:全链路监控 + 成本感知 + 异常降级
二、分阶段实施
阶段1:多租户基础搭建(1~2个月)
| 模块 | 任务 | 技术栈 | KPI |
|---|---|---|---|
| Tenant Manager | 租户隔离、账户管理、配额控制 | Django/Flask + PostgreSQL + Redis | 租户隔离成功率 100% |
| Config per Tenant | 阈值、策略、Agent能力可定制 | JSON配置 + API接口 | 可针对租户动态加载配置 |
| Multi-Model Gateway | 每租户绑定模型策略 | FastAPI + Nginx + Docker | 多租户路由成功率 ≥ 99% |
阶段2:统一检索与 Learning to Rank(2~3个月)
| 模块 | 任务 | 技术栈 | KPI |
|---|---|---|---|
| Retrieval Hub | 向量搜索 + BM25 + KG + Cache | FAISS + ElasticSearch + Redis | 查询召回率 ≥ 90% |
| Feature Builder | 构建交叉特征、上下文特征、行为特征 | Pandas / PySpark | 特征覆盖率 ≥ 95% |
| Learning to Rank | XGBoostRanker / NN 排序 | PyTorch / TensorFlow / XGBoost | NDCG ≥ 0.8 |
阶段3:Policy Engine + Agent Router(2~3个月)
| 模块 | 任务 | 技术栈 | KPI |
|---|---|---|---|
| Policy Engine | 决策逻辑,动态阈值、风险控制、成本感知 | Python + Redis | LLM调用率 ≤ 30% |
| LLM Agent Router | QA / Recommendation / Tool / Search Agents | LangChain + OpenAI / Claude / 本地模型 | 多Agent正确路由率 ≥ 95% |
| 异常降级策略 | 熔断、缓存、直接输出 | Redis / CircuitBreaker | 系统可用性 ≥ 99.9% |
阶段4:AutoML + Agent自博弈(2~3个月)
| 模块 | 任务 | 技术栈 | KPI |
|---|---|---|---|
| AutoML权重优化 | 离线训练 + 自动搜索最佳排序权重 | Optuna / Ray Tune + XGBoost | 排序NDCG提升 5~10% |
| Agent自博弈 | 强化学习策略,优化prompt & tool调用 | RLlib / Stable-Baselines3 | LLM调用成本下降 10~20% |
| A/B实验系统 | 策略对比验证 | MLflow / Weights & Biases | 实验覆盖率 ≥ 80% |
阶段5:数据飞轮 + 自学习闭环(持续)
| 模块 | 任务 | 技术栈 | KPI |
|---|---|---|---|
| Data Flywheel | 用户行为 → 日志采集 → 特征更新 | Kafka / Spark / Delta Lake | 日志完整率 ≥ 95% |
| Offline Training | 离线模型训练 & 权重更新 | PyTorch / TensorFlow | 每周更新模型 ≥ 1次 |
| Online Feedback | 实时反馈偏置 + TTL槽位 | Redis / Python | 偏置收敛率 7天内显著 |
三、成本与监控体系
- 多租户成本感知
- 每租户Token预算 + 成本熔断 + ROI监控
- 全链路监控
- 错误率、延迟、熔断次数、LLM调用率
- 质量指标
- 转化率、用户满意度、反馈偏置收敛、NDCG/CTR/CVR
四、技术栈总结(落地可用)
| 功能 | 技术 | 说明 |
|---|---|---|
| Web / API | FastAPI / Flask | 高并发接口 |
| 数据库 | PostgreSQL + Redis | 租户数据隔离 + 缓存 |
| 搜索 | ElasticSearch + FAISS | 向量 + BM25 |
| LLM | OpenAI / Claude / 本地模型 | Agent化调用 |
| 排序 | XGBoost / PyTorch | Learning to Rank |
| AutoML | Optuna / Ray Tune | 权重自动搜索 |
| 强化学习 | RLlib / Stable-Baselines3 | Agent自博弈 |
| 数据流 | Kafka / Spark / Delta Lake | Data Flywheel |
| 可观测 | Prometheus / Grafana / MLflow | 全链路监控 |
五、KPI体系(可衡量目标)
| 类别 | 指标 | 目标值 |
|---|---|---|
| 系统 | 可用性 | ≥ 99.9% |
| LLM调用 | 调用率 | ≤ 30% |
| 排序 | NDCG / CTR | ≥ 0.8 / 提升 ≥10% |
| 人工干预 | 占比 | ≤ 5% |
| 成本 | 月度 | ≤ 预算 80% |
| 自学习 | 偏置收敛 | 7天内显著区分 |
六、落地策略总结
- 先小租户 / 单业务线试点,确保基础架构稳健
- 阶段性迭代,每阶段输出 KPI & 可视化报告
- 持续优化:AutoML + Agent自博弈 + Data Flywheel
- 可投资展示:架构图 + 演示PPT + 数据飞轮演示
1️⃣ 数据处理与碎片化整合算法
目标:解决大模型数据碎片化问题,使不同来源、不同格式的数据统一可用。
核心逻辑:
- 数据分层
- 原始数据 → 文本 / 表格 / JSON / 二进制
- 层级索引:来源/领域/时间/可信度
- 向量化
- 使用多模态编码器(文本、图像、表格)
- 输出向量统一维度 dd
- 支持增量更新
- 数据融合
- 相似度计算 sim(a,b)=a⋅b∣∣a∣∣⋅∣∣b∣∣sim(a,b) = \frac{a \cdot b}{||a|| \cdot ||b||}
- 聚类或哈希索引(FAISS/HNSW)
- 冲突处理策略:取高可信度、最近更新时间、或多源加权融合
伪代码:
raw_data = load(source)
vectors = encoder.encode(raw_data)
index.add(vectors, metadata=source_info)
def query_vector(q_text):
q_vec = encoder.encode(q_text)
results = index.search(q_vec, top_k=K)
return fuse_results(results)
2️⃣ 权重动态化算法(按领域/场景调度)
目标:实现按领域动态配置模型权重,同时支持离线搜索和在线更新。
核心逻辑:
- 领域划分
- 用户问题 → 领域分类器 → 指定子模型/权重集
- 权重缓存
- LRU 或热度驱动缓存
- 离线预加载热点权重
- 动态混合
- 查询时选择最优子权重组合
- 可根据上下文调整 α 权重
domain = domain_classifier.predict(query)
weights_set = weight_manager.get(domain)
combined_weights = mix(weights_set, alpha_strategy(query))
return combined_weights
3️⃣ 反馈闭环具象化算法
目标:通过用户行为反馈优化模型输出,而不直接改概率,而是引入偏置调整。
核心逻辑:
- 反馈收集
- 点击、停留、纠正、评分 → 转化为偏置向量 bfb_f
- 偏置调整
- 模型输出 logits:o=softmax(Wx)o = softmax(Wx)
- 增加偏置:o′=softmax(Wx+bf)o’ = softmax(Wx + b_f)
- A/B 测试与权重微调
- 定期通过在线实验验证偏置有效性
return softmax(original_logits + feedback_vector)
4️⃣ 多租户 + 数据飞轮算法
目标:支撑 SaaS 多租户环境,利用数据飞轮提升模型能力。
核心逻辑:
- 多租户隔离
- 每个租户独立索引 + 权重子集
- 全局优化策略:可共享通用知识
- 飞轮设计
- 用户数据 → 增量训练 → 模型更新 → 提升搜索/回答准确率 → 收集更多数据
- 自动化 Agent 可自博弈优化权重选择
- 自动权重搜索
- 网格搜索 / 贝叶斯优化 / 强化学习策略选择权重组合
feedback = collect_feedback(tenant)
update_local_model(tenant, feedback)
global_model = aggregate_models([tenant.model for tenant in tenants])
5️⃣ 系统调用流程(整合算法)
- 用户输入 → 查询分类 → 数据检索 → 权重选择
- 模型生成输出 → 应用反馈偏置 → 返回结果
- 收集行为反馈 → 更新域权重 / 子模型 → 加入飞轮循环
整体伪代码:
domain = domain_classifier.predict(user_query)
weights = weight_manager.get(domain, tenant_id)
data_vecs = index.search(encoder.encode(user_query))
raw_output = model.generate(data_vecs, weights)
feedback_bias = feedback_manager.get_bias(user_query, tenant_id)
final_output = adjust_logits(raw_output, feedback_bias)
return final_output
1️⃣ 数据碎片化整合 — 细化算法逻辑
目标:支持异构、多源、增量数据,同时保证大模型可直接调用。
1.1 数据分层与预处理
- 层级设计:
- 原始层:文本、表格、PDF、JSON
- 语义层:文本嵌入向量
- 索引层:向量索引(HNSW、IVF)
- 元数据层:来源、时间、可信度、租户ID
- 数据清洗 & 标准化:
if raw.type == ‘text’:
return normalize_text(raw.content)
elif raw.type == ‘table’:
return table_to_text(raw.content)
elif raw.type == ‘json’:
return json_to_text(raw.content)
1.2 向量化 & 增量更新
- 多模态编码器:
- 文本 → BERT / OpenAI embeddings
- 表格 → TabNet 或转换成文本
- 图像 → CLIP embeddings
- 向量增量更新:
vecs = encoder.encode(new_data)
index.add(vecs, metadata=new_data.metadata)
if index.size > THRESHOLD:
index.rebuild()
1.3 数据融合策略
- 相似度计算:
sim(a,b)=a⋅b∣∣a∣∣∣∣b∣∣sim(a,b) = \frac{a \cdot b}{||a|| ||b||}
- 融合策略:
- 多源加权:
score = sum(sim_i * weight_i) - 冲突决策:最新 > 高可信度 > 平均融合
- 对多租户数据保持隔离
- 多源加权:
2️⃣ 权重动态化 — 细化逻辑
目标:不同领域、不同租户自动选择最优权重组合
2.1 权重分层
- 全局权重:通用知识
- 领域权重:金融、医疗、教育等
- 租户权重:客户定制化
2.2 权重选择逻辑
domain_probs = domain_classifier.predict_proba(query)
domain_weights = {d: weight_manager.get(d, tenant_id) for d in domain_probs.keys()}
# 动态混合
combined = sum(domain_weights[d]*domain_probs[d] for d in domain_weights)
return combined
- 热度缓存策略:
- 最近访问频率高的权重集优先缓存
- 离线批处理预加载热点领域权重
2.3 权重微调与增量训练
- 使用 在线微调 + KL约束 保持全局模型稳定
L=Ltask+λ⋅KL(Pold∣∣Pnew)\mathcal{L} = \mathcal{L}_{task} + \lambda \cdot KL(P_{old} || P_{new})
3️⃣ 反馈闭环 — 细化算法逻辑
目标:用行为反馈优化输出,不直接修改概率,而是引入偏置向量
3.1 收集与量化反馈
- 点击、纠正、评分 → 转换成向量 bfb_f
- 可以按领域或租户区分:
3.2 偏置应用
- 模型输出 logits o=Wxo = W x
- 加入偏置:
o′=softmax(o+bf)o’ = softmax(o + b_f)
3.3 自适应反馈更新
- 增量更新策略:
- 小批量更新:减少过拟合
- 时间衰减:老反馈权重下降
bfnew=γbfold+(1−γ)bfcurrentb_f^{new} = \gamma b_f^{old} + (1-\gamma) b_f^{current}
4️⃣ 多租户与数据飞轮 — 细化逻辑
4.1 多租户隔离
- 每个租户:
- 独立向量索引 + 权重子集
- 全局模型共享通用权重
- 隔离策略:
4.2 数据飞轮
- 用户查询 → 收集反馈
- 增量更新租户权重 & 全局模型
- 提升回答准确率 → 产生更多查询 → 收集更多数据
4.3 自动权重搜索
- 使用 强化学习或贝叶斯优化:
- 状态:查询上下文 + 租户ID
- 动作:选择权重组合
- 奖励:回答准确率 / 用户满意度
update_weights(action)
5️⃣ 系统整体调用流程 — 精细化
|
v
[领域分类器] —> [选择权重集]
| |
v v
[向量检索索引] [动态权重混合]
| |
——–> [模型生成 logits]
|
v
[应用反馈偏置向量]
|
v
[返回结果]
|
v
[收集行为反馈]
|
v
[增量更新租户+全局模型]
|
v
[数据飞轮]
💡 这个版本已经把 数据结构、索引、权重选择、偏置策略、增量更新、飞轮循环 每一层算法都拆清楚了,几乎可以直接落地写工业级代码。
- 数据结构设计(索引格式、元数据、向量存储)
- 权重动态化策略(领域/租户混合、缓存策略、热度调度)
- 反馈闭环数学公式(偏置向量、增量更新公式、衰减机制)
- 增量训练/在线微调算法
- Agent自博弈优化权重的强化学习策略
- 多租户隔离 + 数据飞轮的调度逻辑
下面给你一个 工业级详细算法逻辑说明,每一块都尽量精确到可落地伪代码和数学公式。
1️⃣ 数据碎片化整合 — 工业级细化
1.1 数据分层与结构
| 层级 | 内容 | 数据结构示例 |
|---|---|---|
| 原始层 | 文本、表格、JSON、PDF等 | raw_data{id, type, content, source, timestamp} |
| 元数据层 | 来源、租户ID、可信度、更新次数 | metadata{tenant_id, domain, confidence, update_ts} |
| 向量层 | 文本/表格/图像向量 | embedding{id, vector, metadata_id} |
| 索引层 | 向量索引(FAISS/HNSW/IVF) | index.add(vector, id) |
1.2 向量化 & 索引构建
for d in data_list:
vec = encoder.encode(d.content)
index.add(vec, metadata=d.metadata)
- 增量更新:
vec = encoder.encode(new_data.content)
index.add(vec, metadata=new_data.metadata)
if index.size > THRESHOLD:
index.rebuild() # 重建索引以优化搜索速度
- 相似度融合公式:
scorei=∑jsim(veci,vecj)⋅wjscore_i = \sum_{j} \text{sim}(vec_i, vec_j) \cdot w_j
其中 wjw_j 可基于可信度、时间衰减等权重。
2️⃣ 权重动态化 — 工业级细化
2.1 权重分层与选择
- 权重层次:
- 全局权重 WgW_g
- 领域权重 WdW_d
- 租户权重 WtW_t
- 动态组合公式:
Wfinal=αgWg+αdWd+αtWtW_{final} = \alpha_g W_g + \alpha_d W_d + \alpha_t W_t
其中 αg+αd+αt=1\alpha_g + \alpha_d + \alpha_t = 1,可由上下文/历史查询动态计算。
2.2 热度缓存策略
if cache.exists(domain, tenant_id):
return cache.fetch(domain, tenant_id)
else:
weights = load_weights(domain, tenant_id)
cache.update(domain, tenant_id, weights)
return weights
2.3 增量微调(在线更新)
L=Ltask+λKL(Pold∣∣Pnew)\mathcal{L} = \mathcal{L}_{task} + \lambda KL(P_{old} || P_{new})
- 防止微调导致全局知识遗忘
- 小批量在线更新权重
3️⃣ 反馈闭环 — 工业级细化
3.1 反馈收集
- 用户行为:
- 点击 → +1
- 停留时间 → +α
- 纠正 → -1
- 用户评分 → +β
- 偏置向量生成:
bf=∑iwi⋅fib_f = \sum_i w_i \cdot f_i
3.2 偏置应用
return softmax(logits + feedback_vector)
3.3 增量更新与衰减
bfnew=γ⋅bfold+(1−γ)⋅bfcurrentb_f^{new} = \gamma \cdot b_f^{old} + (1-\gamma) \cdot b_f^{current}
- γ∈[0,1]\gamma \in [0,1] 控制历史反馈衰减
- 可按领域或租户独立计算
4️⃣ 多租户 + 数据飞轮
4.1 多租户隔离
tenant_weights = {tenant_id: WeightSet() for tenant_id in tenants}
4.2 数据飞轮
- 查询 → 检索/生成 → 收集反馈
- 增量更新租户模型 + 全局模型
- 优化权重选择策略 → 产生更多查询 → 循环
4.3 权重自博弈优化(强化学习)
- 状态:
(query_context, tenant_id, domain) - 动作:选择权重组合
(W_g, W_d, W_t) - 奖励:用户满意度 / 准确率
weights = mix_weights(action)
reward = evaluate_output(output, user_feedback)
RL_agent.update(state, action, reward)
5️⃣ 全流程调用 — 工业级伪代码
# 1. 领域分类
domain = domain_classifier.predict(query)
# 2. 权重动态选择
weights = get_weights(domain, tenant_id)
combined_weights = mix(weights.global, weights.domain, weights.tenant, alpha_strategy(query))
# 3. 向量检索
vec = encoder.encode(query)
candidates = tenant_index[tenant_id].search(vec, top_k=K)
# 4. 模型生成 logits
logits = model.generate(candidates, combined_weights)
# 5. 反馈闭环偏置
feedback_vec = feedback_manager.get_bias(query, tenant_id)
final_output = apply_feedback(logits, feedback_vec)
# 6. 收集行为反馈
feedback_manager.collect(query, tenant_id, user_behavior)
# 7. 数据飞轮 & 权重自博弈
RL_agent.update_state(query, tenant_id, user_feedback)
return final_output
- 数据结构精确设计(字段、类型、索引方式)
- 向量索引与检索逻辑(HNSW/FAISS/IVF参数)
- 权重调度具体算法(α值计算、缓存策略、淘汰机制)
- 反馈闭环公式化(历史衰减、动态偏置、增量更新公式)
- 多租户隔离策略(本地索引、全局权重、租户权限控制)
- 数据飞轮 + Agent自博弈优化(状态定义、动作空间、奖励函数)
- 具体伪代码实现 + 流程逻辑(每步都有输入/输出、函数接口、更新机制)
我可以帮你做到这个层级:
1️⃣ 数据层(工业落地级)
数据结构设计
id: str # 唯一ID
type: str # text/table/json/image/pdf
content: str # 原始内容
source: str # 数据来源
tenant_id: str # 租户
timestamp: datetime # 更新时间
class MetaData:
raw_id: str
tenant_id: str
domain: str # 分类领域
confidence: float # 可信度评分 0-1
update_ts: datetime
usage_count: int # 被查询次数
class VectorEntry:
vec: np.array # 向量
metadata: MetaData
索引设计
- 使用 HNSW 或 IVF 向量索引
- 支持增量添加和删除
- 支持多租户隔离索引(每租户独立一个索引)
2️⃣ 权重动态调度(工业落地级)
权重分层
- 全局权重 WgW_g
- 领域权重 WdW_d
- 租户权重 WtW_t
权重组合公式
Wfinal=αgWg+αdWd+αtWtW_{final} = \alpha_g W_g + \alpha_d W_d + \alpha_t W_t
α值动态计算策略
# query与领域匹配度
domain_probs = domain_classifier.predict_proba(query)
alpha_d = domain_probs.max() # 最高概率对应领域权重
alpha_g = 0.5 * (1 – alpha_d)
alpha_t = 0.5 * (1 – alpha_d)
return alpha_g, alpha_d, alpha_t
缓存与淘汰策略
- LRU缓存权重集合
- 高频领域预加载
- 低访问权重自动落盘
if cache.exists(domain, tenant_id):
return cache.fetch(domain, tenant_id)
weights = load_weights(domain, tenant_id)
cache.add(domain, tenant_id, weights)
return weights
3️⃣ 反馈闭环(工业落地级)
反馈偏置向量生成
b_f = np.zeros(VECTOR_DIM)
for f in feedback_list:
# f = (type:click/correction/score, weight)
b_f += f.weight * feedback_embedding(f)
return b_f
偏置应用公式
logits′=softmax(logits+bf)logits’ = softmax(logits + b_f)
增量更新 + 衰减
bfnew=γ⋅bfold+(1−γ)⋅bfcurrent,γ∈[0,1]b_f^{new} = \gamma \cdot b_f^{old} + (1-\gamma) \cdot b_f^{current},\quad \gamma \in [0,1]
4️⃣ 多租户 + 数据飞轮
多租户隔离
tenant_index = {tenant_id: LocalIndex() for tenant_id in tenants}
数据飞轮流程
- 用户查询 → 检索 + 生成 → 收集行为反馈
- 更新租户权重与本地索引
- 聚合更新全局模型
- 强化学习优化权重组合 → 产生更多查询 → 循环
Agent自博弈强化学习
- 状态:
(query_context, tenant_id, domain, last_reward) - 动作:选择权重组合
(α_g, α_d, α_t) - 奖励:
reward = accuracy*0.5 + user_satisfaction*0.5
weights = combine_weights(action)
reward = evaluate(output, user_feedback)
RL_agent.update(state, action, reward)
5️⃣ 系统调用流程(工业落地级)
domain = domain_classifier.predict(query)
# 权重选择
W_g, W_d, W_t = get_weight(domain, tenant_id)
alpha_g, alpha_d, alpha_t = alpha_strategy(query, tenant_id)
W_final = alpha_g*W_g + alpha_d*W_d + alpha_t*W_t
# 向量检索
query_vec = encoder.encode(query)
candidates = tenant_index[tenant_id].search(query_vec, top_k=K)
# 模型生成
logits = model.generate(candidates, W_final)
# 反馈闭环
feedback_vec = feedback_manager.get_bias(query, tenant_id)
output = apply_feedback(logits, feedback_vec)
# 收集反馈
feedback_manager.collect(query, tenant_id, user_behavior)
# 数据飞轮 & RL优化
RL_agent.update_state(query, tenant_id, user_feedback)
return output
💡 这一版已经是 每一层都落地到具体数据结构、向量索引、权重策略、偏置公式、增量更新、RL优化动作与奖励,几乎可以直接开发实现。
TSPR-WEB-LLM-HIC v4.0 工业级算法蓝图文档
1️⃣ 数据层设计(Data Layer)
1.1 数据结构
| 类名 / 表名 | 字段名 | 类型 | 描述 |
|---|---|---|---|
RawData |
id |
str | 全局唯一ID |
type |
str | 数据类型(text, table, json, image, pdf) | |
content |
str | 原始内容 | |
source |
str | 数据来源 | |
tenant_id |
str | 租户ID | |
timestamp |
datetime | 数据更新时间 | |
MetaData |
raw_id |
str | RawData对应ID |
tenant_id |
str | 租户ID | |
domain |
str | 分类领域 | |
confidence |
float | 可信度评分0~1 | |
update_ts |
datetime | 更新时间 | |
usage_count |
int | 被查询次数 | |
VectorEntry |
vec |
np.array[dim] | 向量化表示 |
metadata |
MetaData | 元数据 |
1.2 向量索引策略
- 算法选择:HNSW / FAISS IVF
- 索引参数:
- HNSW:
M=32, ef_construction=200, ef_search=50 - IVF:
nlist=1024, nprobe=8
- HNSW:
- 索引操作:
- 增量添加:
index.add(vector, metadata) - 删除:
index.remove(id) - 重建策略:当增量数据超过阈值 THRESHOLD 时触发
- 增量添加:
1.3 向量融合逻辑
scorei=∑jsim(veci,vecj)⋅wjscore_i = \sum_{j} sim(vec_i, vec_j) \cdot w_j
sim= 余弦相似度w_j= 元数据权重(可信度、时间衰减、租户优先级)
2️⃣ 权重动态化模块(Weight Management)
2.1 权重层次
| 层级 | 描述 |
|---|---|
| 全局权重 W_g | 通用知识,所有租户共享 |
| 领域权重 W_d | 金融/医疗/教育等领域权重 |
| 租户权重 W_t | 每个租户定制化权重 |
2.2 权重组合公式
Wfinal=αgWg+αdWd+αtWtW_{final} = \alpha_g W_g + \alpha_d W_d + \alpha_t W_t
- αg+αd+αt=1\alpha_g + \alpha_d + \alpha_t = 1
- α值动态计算策略:
alpha_d = max(domain_probs.values())
alpha_g = 0.5 * (1 – alpha_d)
alpha_t = 0.5 * (1 – alpha_d)
2.3 缓存与淘汰策略
- LRU缓存高频权重
- 低访问权重落盘,按访问频率淘汰
- 离线批量预加载热点领域权重
2.4 增量微调公式
L=Ltask+λKL(Pold∣∣Pnew)\mathcal{L} = \mathcal{L}_{task} + \lambda KL(P_{old} || P_{new})
- 小批量在线更新,防止全局知识遗忘
3️⃣ 反馈闭环模块(Feedback Loop)
3.1 反馈量化
| 行为 | 权重 w_i |
|---|---|
| 点击 | +1 |
| 停留时间 | +α |
| 纠正 | -1 |
| 用户评分 | +β |
3.2 偏置向量生成
bf=∑iwi⋅fib_f = \sum_i w_i \cdot f_i
- f_i = feedback embedding
- b_f维度与模型logits维度一致
3.3 偏置应用
logits′=softmax(logits+bf)logits’ = softmax(logits + b_f)
3.4 增量更新 + 衰减
bfnew=γbfold+(1−γ)bfcurrent,γ∈[0,1]b_f^{new} = \gamma b_f^{old} + (1-\gamma) b_f^{current}, \quad \gamma \in [0,1]
4️⃣ 多租户 + 数据飞轮模块(Multi-Tenant & Data Flywheel)
4.1 多租户隔离
- 每租户独立向量索引 & 权重子集
- 全局模型共享通用权重
- 权限控制:租户只能访问自己索引与权重
tenant_weights = {tenant_id: WeightSet() for tenant_id in tenants}
4.2 数据飞轮
- 用户查询 → 检索 + 模型生成
- 收集行为反馈 → 更新租户模型
- 聚合更新全局模型 → 提升回答准确率
- 产生更多查询 → 循环
4.3 RL自博弈优化权重
| 项目 | 描述 |
|---|---|
| 状态 | (query_context, tenant_id, domain, last_reward) |
| 动作 | 选择权重组合 (α_g, α_d, α_t) |
| 奖励 | reward = accuracy*0.5 + user_satisfaction*0.5 |
weights = combine_weights(action)
reward = evaluate(output, user_feedback)
RL_agent.update(state, action, reward)
5️⃣ 系统调用流程(工业落地级)
domain = domain_classifier.predict(query)
# 权重选择
W_g, W_d, W_t = get_weight(domain, tenant_id)
alpha_g, alpha_d, alpha_t = alpha_strategy(query, tenant_id)
W_final = alpha_g*W_g + alpha_d*W_d + alpha_t*W_t
# 向量检索
query_vec = encoder.encode(query)
candidates = tenant_index[tenant_id].search(query_vec, top_k=K)
# 模型生成 logits
logits = model.generate(candidates, W_final)
# 反馈闭环
feedback_vec = feedback_manager.get_bias(query, tenant_id)
output = apply_feedback(logits, feedback_vec)
# 收集反馈
feedback_manager.collect(query, tenant_id, user_behavior)
# 数据飞轮 & RL优化
RL_agent.update_state(query, tenant_id, user_feedback)
return output
💡 说明:
- 每一模块都有字段、类型、公式、策略、缓存与更新逻辑
- 系统调用流程展示了全链路数据流 + 权重 + 反馈 + RL优化
- 该蓝图可直接交给研发团队进行开发,实现 TSPR-WEB-LLM-HIC v4.0